 德阳汽车网
德阳汽车网出租司机先别慌 智驾行业的程序员们会更早被AI抢饭碗
每项新技术从诞生到推广,会经历各个不同的阶段,也会面临各种不同的声音。研发者为了找到技术最优解,可能会放弃已有多年的努力;而商业机构则更偏重于判断技术落地的时机,以在合适的时机谋取最大的利益。
关于智能驾驶,国内各主机厂商们就一度有过很深的认知分歧。支持者认为它可以带来「遥遥领先」的体验,而反对者则抛出过「臭搞技术的」、「自动驾驶都是忽悠」等言论以表达不屑。
2024 年,随着基于「端到端」的特斯拉智能驾驶软件 FSD V12 版本正式推送,中国汽车厂商们对智能驾驶的态度,终于开始收敛了。
以新势力造车代表蔚小理为例,各家对于「端到端」技术的追逐显然开始发力了。
小鹏提出将端到端的大模型引入智驾系统,并表示今年要在智能化和训练数据上投入 42 亿元,目标是以后可以做到「两天一次内部 OTA」。这是过去依靠人类维护数十万行智能驾驶代码的工作方式所不敢想象的效率提升。
蔚来也于近期重组了智能驾驶研发部,将传统的感知和规模团队合并为大模型团队,核心也是推动基于神经网络的范式迭代。
甚至过去被调侃为「抠厂」的理想,也在近期频繁为智能化研发造势。CEO 李想亲自为「端到端」研发站台,搬出诺贝尔经济学家的快慢思考理论,以说明自家团队找到了解决自动驾驶 conner case 的方向。
那么,让各家厂商从非共识走向共识的端到端,为什么会有这么大的魔力?它如何改变了智能驾驶行业的范式,又将带来怎样的机遇和调整?
智驾的 GPT 时刻已经来过了
国内各厂商们迅速形成共识的重要原因,是特斯拉率先交出了一份让人羡慕的端到端答卷。
今年 3 月,特斯拉正式推送了智能驾驶软件 FSD V12.3 版本。这个版本的最大改变,就是把整个智驾系统工作的动力,从人类编写的代码,切换成了基于神经网络的 AI 大模型。马斯克用「Video in to Control out」来形容这种新的工作范式,即:AI 根据自己「看」到的路面信息,直接输出驾驶操作,也就是业界常说的「端到端」(End-to-End)。
上个月,何小鹏在加州体验了 FSD V12.3.6 版本。用他的话来说,FSD「很多路况处理都很丝滑」。这正是 AI 神经网络相比于代码驱动的最大优势所在:在不同城市、不同路况下,大幅提高智驾系统的泛化学习能力。
翻译成国内消费者们更熟悉的广告营销话术就是:全国(全球)都能开。

华为在去年9月喊出「全国都能开」的宣传语 | 来源:极客公园
当然,这个结论在现阶段还只是一个美好的心愿。在实际操作过程中,还需要数据、算法、算力等 AI 基础设施的全力加持和训练,才可能接近「AI 变得和人类驾驶员一样聪明」这个目标。
但对于同行们来说,FSD V12 版本意义重大。它验证了神经网络真的可以取代人类编写的代码,甚至可以做得更好更高效。
这意味着不用再等 N 年,智能驾驶行业里的 ChatGPT 时刻其实已经到来了。想想阿里张勇曾经说过的那句话:所有软件都值得用 AI 重做一遍。FSD V12 正是给了同行一个新的方向和信心:所有智驾的技术栈,都可以用端到端重做一遍。
在 FSD V12 beta 版本发布的时候,马斯克说过,这一版本把前一版本的 30 万行代码压缩到了 2000 行,相当于不到百分之一的水平。
新技术栈里的智驾比拼,不会演变为比谁人更多的反创新内卷游戏。如果 AI 的效率真能达到何小鹏所说的两天一次内部 OTA,那逐条写规则、改 bug 的人海战术就可以宣布彻底过时。
所以智驾行业还需要那么多程序员吗?笔者无法给出准确的答案,但可以肯定的是,智驾程序员的工作内容也将发生一系列改变。只会写 if else 规则的程序员,大概率会早于出租车、网约车司机们被 AI 取代。
困在数据里
在投资机构辰韬资本上个月发布的《端到端自动驾驶行业研究报告》中,30 余位自动驾驶行业受访者,只有 13% 表示对端到端技术持相对谨慎的「观望」态度,其余均表达了更积极的「预研」甚至「全力投入」的态度。端到端已经在行业从业者里成为了共识。
但事实上,目前还没有任何一家企业(包括特斯拉在内),可以做到「原教旨主义端到端」。也就是把自动驾驶的所有环节都集中在同一个大的模型里,真正达到和人类一样的「输入视觉信号,输出踏板和方向盘操作」。
大部分国内主机厂现阶段所做的核心努力,是打通感知和决策模块。这其中的关键,就是取消模块之间的人工定义结果,更多用特征向量传递无损信息。
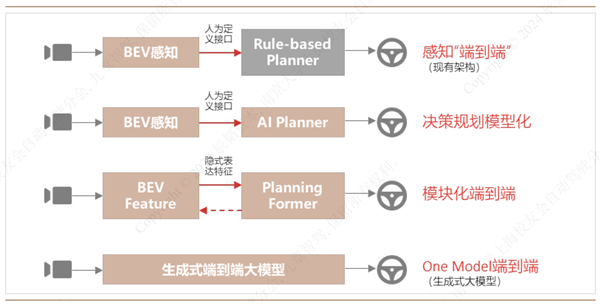
端到端自动驾驶的架构演进示意图 | 图片来源:辰韬资本
在端到端之前,传统自动驾驶架构来源于机器人领域,分为感知、规划、控制等不同模块。不同模块由不同团队开发,在模块与模块之间,主要通过人工定义的接口传递信息。举个最简单的例子,对于车辆是否压线行驶这个现象,在传统感知模块里就可以用最简单的计算机二进制语言进行表征。
而打通感知和决策模块的最大好处,就是可以涵盖更多现实世界中规则无法准确描述的「灰度场景」。例如,当你开车时,并不需要知道前车精确的行驶速度,或者它是否压线,只需要关注相对位置变化就好。
在这个基础上,基于生成式 AI 的理论,期待神经网络模型也能在大量输入后产生智能涌现,成为 AI 智能体。
这一切的基础都来源数据,也就是「喂」给模型的训练素材。但是,和基于文字的语言大模型不同,智驾模型并不容易找到足够的公开视频数据作为训练素材。
前述《端到端自动驾驶行业研究报告》显示,目前规模最大的公开数据集只有 1200 小时数据。而根据马斯克 2023 年的说法,特斯拉在端到端的初期,就投入了近 4 万小时的视频进行训练。
相比其他车企,特斯拉数据的优势主要就在于量产车多。
目前,特斯拉在全球共交付了超过 600 万辆汽车,而在中国积极布局智驾的新势力里,量产车的数量只是特斯拉的零头。再加上一贯的极简 SKU 和全量预埋的智驾硬件,让数据收集变得更加容易。
国内此前的常规做法,通常是依靠人工获取道路信息。但是,要训练出一个聪明的端到端模型,也需要尽量涵盖足够多边缘场景(conner case)的数据。由于边缘场景的出现非常随机,有厂商曾经表示,仅靠人工数据采集,只能得到大约 2% 的有限数据。
此外,和特斯拉相比,国内厂商往往有着更复杂的 SKU。而不同车型之间,由于车辆尺寸、传感器布局等不同,模型中的相关参数也需要重新进行对齐。
以华为系为例,鸿蒙智行过去一年多的时间里展现出了极强的终端销售能力,但对于华为车 BU 服务的不同品牌、不同型号的车型来说,端到端落地后仍然需要工程师进行对齐和交付工作。对于有 2 个品牌 9 款车型的蔚来来说,同样如此,他们把集成团队重组到了交付团队中。
在Sora发布后,马斯克发推表示特斯拉用AI模拟真实世界驾驶 | 图片来源:X截图
有一种观点是,以 Sora 为代表的文生视频类产品有可能成为端到端模型的素材来源。但哪怕对马斯克来说,用 AI 生成的内容训练 AI,也还没有得到公开认可。毕竟数据的数据对于模型训练太重要了。要知道,一向对人力成本极致「抠门」的马斯克,当年也在纽约雇了 1000 人团队,来为特斯拉的道路视频数据进行标注。
别被马斯克「带沟里」
听起来,转向端到端是一个自然而然的事,但删除 30 万行代码,对过往组织架构打散重组,绝对不是一个容易做出的决定。事实上,连马斯克也是半撞大运的走上了这条路。那个在 2022 年底第一次向他提出要学习 ChatGPT 搭建智能驾驶神经网络的工程师,差一点就被老马调去解决 Twitter 收购后的其他问题了。
训出了端到端模型,相应的支持体系(包括算力等)也要足够高效。蔚来智能驾驶研发副总裁任少卿在接受《腾讯深网》采访时,表示如果没有基本能力就强行上端到端,就等于在用「毒药」。
他说:「如果你原来的代码架构足够清晰,你的(debug)测试量可能只有 1%。原先你花三天重新测 1%,现在不好意思,你花三天要重测 100%。所以你的数据验证体系效率要足够高。」
但是千万别直接被特斯拉带到沟里,端到端此刻只是证明了它具备提高工作效率的可能,但并没有证明它就是通往自动驾驶的最终解法。
这一点和业界关于 Scaling Law 能否通向物理世界 AGI(通用人工智能)的认知是一致的:可以肯定,生成式人工智能可以具备更高的智能,但是否可以理解物理规律,并在自动驾驶、机器人等领域应用,学界尚无定律。在《端到端自动驾驶行业研究报告》,有超过一半的从业者不认为端到端是自动驾驶技术的终局解决方案。
对于自研智驾的主机厂来说,现阶段最务实的做法,还是依托端到端让智驾能力多快好省地落地。至于智驾软件订阅这件事,也许还需要更长的路。毕竟在中国市场上,硬件往往比软件和服务好卖。
当然,大概率也没有那么多人想成为马斯克那样的创新赌徒。放着好好的廉价车型不研发,去豪赌 Robotaxi,发布一推迟市值能跌上千亿美元。更多的普通玩家,只是希望搭载了端到端的智驾软件,能帮助硬件卖得更好。当然,如果还能顺便卖得更贵,那就是最美妙的事了。
版权声明
本文仅代表作者观点,不代表本站立场。
部分文章来源网络,如有侵权,请联系删除。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。